
Proteomics Basics: Must-Know Questions for Beginners
Proteomics is a rapidly growing field that focuses on the large-scale study of proteins—complex molecules essential for virtually every biological process. For beginners, understanding the basics of proteins and proteomics is key to grasping how these biomolecules drive cellular functions and how scientists analyze them to uncover insights into health and disease. This article explores fundamental proteomics concepts, from protein structures and functions to advanced quantification techniques used in research.
- What Are Proteins? Understanding Their Structure and Function
- What Is Proteomics?
- Why Is a Protein Database Necessary for Proteomics Research?
- Common Protein Databases: Choosing the Right One
- Labeled Quantitative Proteomics vs. Label-Free Quantitative Proteomics
- DDA vs. DIA in Label-Free Quantification: A Comparative Analysis
What Are Proteins? Understanding Their Structure and Function
A protein is a large, complex molecule that plays a critical role in virtually every biological process within living organisms. Proteins are made up of smaller building blocks called amino acids, which are linked together in specific sequences to form long chains. These chains fold into unique three-dimensional structures, which determine each protein’s specific function.
Protein Structure:
- Primary Structure: The specific sequence of amino acids in a polypeptide chain.
- Secondary Structure: Local folding patterns like alpha helices and beta sheets, stabilized by hydrogen bonds.
- Tertiary Structure: The overall 3D shape of the protein, formed by interactions between the side chains of amino acids.
- Quaternary Structure: The arrangement of multiple polypeptide chains, if the protein is made up of more than one subunit.
Key Functions of Proteins:
- Structural Support: Proteins provide structure and support to cells and tissues. Examples include collagen in skin and bones, and keratin in hair and nails.
- Enzymatic Activity: Many proteins are enzymes, which catalyze biochemical reactions in the body. Enzymes are essential for metabolism, digestion, and DNA replication.
- Transport and Storage: Proteins help transport molecules throughout the body. For example, hemoglobin transports oxygen in the blood.
- Immune Defense: Antibodies are proteins that help the immune system recognize and neutralize pathogens like bacteria and viruses.
- Hormonal Signaling: Some proteins function as hormones, such as insulin, which regulates blood sugar levels.
- Movement: Proteins like actin and myosin are responsible for muscle contraction and movement.
What Is Proteomics?
Proteomics is the large-scale study of proteins, focusing on their structure, function, and interactions within an organism. It involves the comprehensive analysis of the proteome, which is the complete set of proteins produced or modified by an organism, tissue, or cell at a specific time. Since proteins are the primary executors of cellular functions, proteomics is crucial for understanding biological processes and disease mechanisms.
Key Aspects of Proteomics:
- Protein Identification: Proteomics aims to identify all the proteins present in a sample. This involves detecting protein sequences, determining which genes are being expressed, and how proteins are modified after their synthesis (post-translational modifications, or PTMs).
- Protein Quantification: Beyond identification, proteomics also measures the abundance of proteins in different samples or conditions. This can help in understanding protein expression levels during processes like cell development, disease progression, or response to drugs.
- Protein Structure and Function: Proteomics explores the 3D structures of proteins and their domains, giving insights into how proteins perform their specific functions in the body.
- Protein Interactions: Proteins rarely work in isolation. Proteomics studies protein-protein interactions and how they form complexes or networks to carry out biological activities.
Why Is a Protein Database Necessary for Proteomics Research?
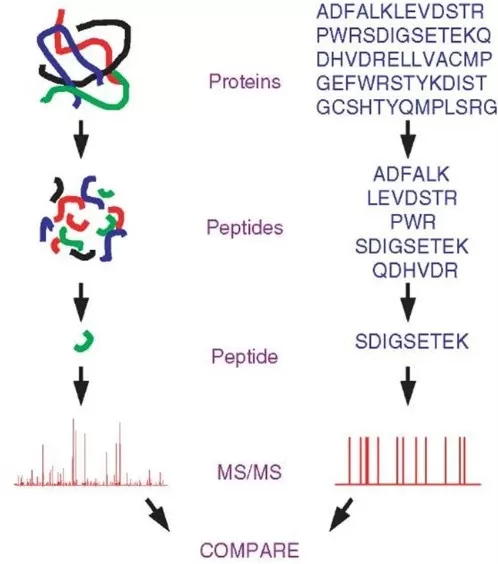 The principle behind protein identification relies on comparing theoretical peptide MS/MS spectra with those obtained experimentally. For example, trypsin specifically cleaves at lysine and arginine residues, allowing for the generation of theoretical peptide spectra based on known amino acid sequences from a database. These theoretical spectra are then matched against experimentally generated spectra to identify peptides and, subsequently, proteins. Without a protein database, it would be impossible to generate these theoretical spectra, making protein identification through peptide matching infeasible.
The principle behind protein identification relies on comparing theoretical peptide MS/MS spectra with those obtained experimentally. For example, trypsin specifically cleaves at lysine and arginine residues, allowing for the generation of theoretical peptide spectra based on known amino acid sequences from a database. These theoretical spectra are then matched against experimentally generated spectra to identify peptides and, subsequently, proteins. Without a protein database, it would be impossible to generate these theoretical spectra, making protein identification through peptide matching infeasible.
Common Protein Databases: Choosing the Right One
a. UniProt (Universal Protein Resource):
UniProt is the most recommended database for proteomics research. It is a comprehensive resource for protein sequences and functional information, encompassing protein data from all organisms. UniProt consists of three main sections:
- UniProtKB (Knowledgebase): Contains protein sequences, annotations, and references.
- Swiss-Prot: A high-quality, manually curated database with expert annotations.
- TrEMBL: A large repository of automatically annotated sequences.
b. NCBI Protein Database:
The NCBI Protein Database is another widely used resource, though it is not specifically designed for proteomics. It contains a broad range of protein sequences and structural data but may not be as focused or comprehensive as specialized proteomics databases like UniProt. One of its limitations is the higher redundancy of protein sequences.
c. Species-Specific Genome or Transcriptome Databases:
For organisms with limited or non-standard annotations, species-specific genome or transcriptome databases can be used to translate nucleotide sequences into protein sequences for proteomic analysis. These databases can provide more comprehensive protein information for less commonly studied organisms. However, for most cases, it is still recommended to use databases specifically designed for proteomics, such as UniProt or the NCBI Protein Database, to ensure more complete and reliable protein identification.
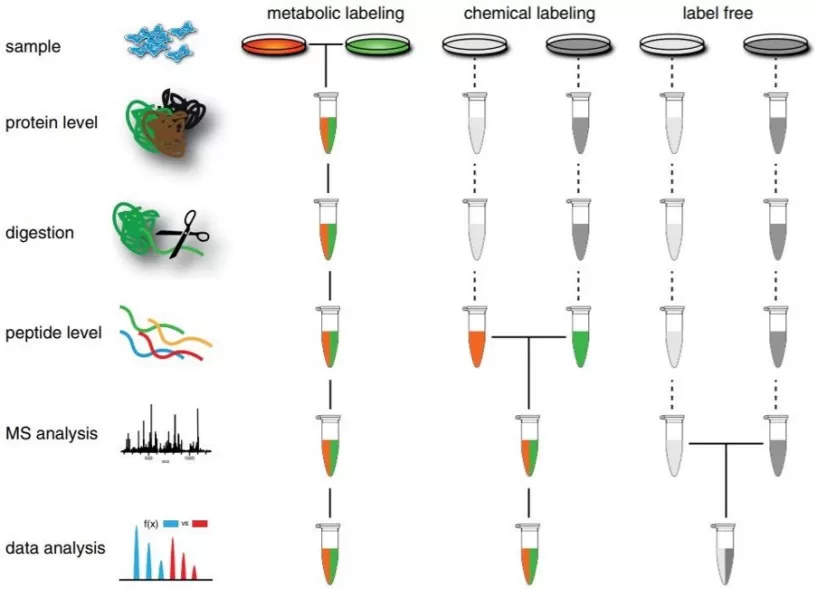
Labeled Quantitative Proteomics vs. Label-Free Quantitative Proteomics
A. Labeled Quantitative Proteomics:
Labeled quantitative proteomics typically employs chemical reagents that covalently bind to the N-terminal or lysine residues of proteins or peptides, such as iTRAQ (isobaric tags for relative and absolute quantification) or TMT (tandem mass tags). These techniques add isotopic labels to proteins or peptides, allowing for the differentiation of proteins across multiple samples based on the mass spectrometer-detectable labels.
TMT isotopic labels consist of three parts: a mass reporter group, a reactive group, and a balance group. During TMT analysis, the reactive group binds covalently to the free amino groups of the N-terminus or lysine side chains of peptides, labeling the peptides for mass spectrometry (MS) detection. In the first stage of mass spectrometry (MS1), peptides from different samples labeled with TMT tags appear with the same mass-to-charge ratio (m/z) due to the mass balance group. In the second stage (MS2), the reporter ions, which have different masses, are released from the peptides, generating distinct reporter ion peaks in the low-mass region. By detecting these reporter ions, the intensity of each ion can be used to quantify the same peptide across different samples.
B. Label-Free Quantitative Proteomics (LFQ):
Label-free quantitative proteomics (LFQ) does not use isotopic labeling but instead relies on comparing the intensity of protein spectral peaks across different samples. This approach involves normalization and statistical analysis and is particularly suitable for relative quantification of protein expression levels, especially when sample availability is limited or when high-throughput analysis is required.
Workflow for Label-Free Quantitative Proteomics
The general workflow for LFQ consists of five major steps: sample collection, total protein extraction, enzymatic digestion of proteins, mass spectrometry detection, and bioinformatics analysis. First, the samples are processed, and proteins are extracted and digested into peptides using trypsin. The digested peptide samples are then analyzed by mass spectrometry, and the resulting MS data are searched against a protein database to identify and quantify proteins. Finally, differential proteins are selected, followed by bioinformatics analysis to explore and interpret the proteomics data from multiple perspectives.
DDA vs. DIA in Label-Free Quantification: A Comparative Analysis
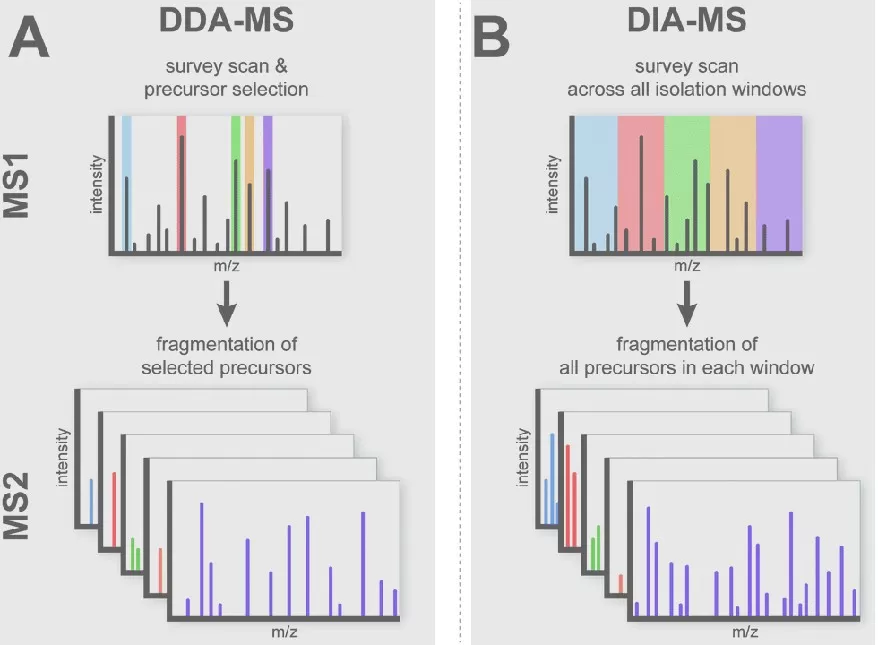
A. Data-Dependent Acquisition (DDA):
In DDA, the acquisition process consists of a full MS1 scan followed by several MS2 scans. The mass spectrometer selects precursor ions from the MS1 spectrum based on intensity, typically prioritizing the most abundant ions, which are fragmented and analyzed to generate MS2 spectra. DDA is one of the most widely used and well-established scanning modes in proteomics research. However, its primary limitation is its bias towards more abundant molecules, which can result in missing lower-abundance molecules. This randomness can negatively impact the reproducibility of results.
B. Data-Independent Acquisition (DIA):
In DIA, the mass range (typically 300-1800 m/z) of the peptides is divided into several windows, and for each scan cycle, one full MS1 scan is followed by multiple MS2 scans. In DIA, all precursor ions within each window are fragmented simultaneously, producing mixed MS2 spectra that contain fragment ions from all peptides in that window. Unlike DDA, where MS2 spectra correspond to selected individual precursor ions, DIA generates MS2 spectra for all ions in a given window, regardless of their abundance in the MS1 scan. This approach allows for more comprehensive and reproducible quantification of both high- and low-abundance peptides.
Next-Generation Omics Solutions:
Proteomics & Metabolomics
Ready to get started? Submit your inquiry or contact us at support-global@metwarebio.com.
